-- 发布时间:10/10/2003 11:37:00 AM
-- [zz]XML相关规范之间的关系
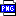 此主题相关图片如下:
此主题相关图片如下: Diagramming the
Diagramming the 原文位于 http://www.xml.com/lpt/a/2003/10/08/family.html
XML Family
By Daniel Zambonini
In this article we'll introduce some of the XML family members and discuss how they relate to one another. We'll then use these technologies to create a diagram of their relationships in order to demonstrate how they work together in practice. Of the hundreds of XML technologies in use, we'll limit the scope of this article to the technologies used in the creation of the diagram.
XML
XML (eXtensible Markup Language) consists of a small set of rules which define a structured, text-based syntax for representing data. It isn't a language as such; rather it is a meta-language, a common syntax that can be shared across diverse standards and data models. But if XML doesn't really do anything, why have so many languages adopted the XML syntax? At a basic level, XML is
Related Reading
Learning XML, 2nd Edition
By Erik T. Ray
Table of Contents
Index
Sample Chapter
Simple -- easy to learn and use, especially for users familiar with HTML.
Flexible -- can be used in many situations, from graphics, to communication protocols, to raw data.
Open -- no licensing or pricing restrictions, vendor, or platform lock-ins.
W3C XML Schema
W3C XML Schema allows us to create vocabularies with XML by adding further restrictions to the core XML rules. These restrictions mainly consist of valid names for elements and attributes; which elements can be used inside another; valid repetition of elements; and the type of data for elements and attributes.
Schemas allow us to publish and share these rules for new vocabularies and check the validity of any files which claim adherence to a particular vocabulary. Unlike Document Type Definitions, XML Schema uses the XML syntax, allowing us to parse and query XML Schema files using standard XML tools. (See the XML.com article "Using W3C XML Schema" for more detail.)
Namespaces
Given the ability to create different vocabularies in XML, together with a feature that allows the combination of vocabulary elements into a single file, we are presented with the name collision problem.
For example, an XML schema for books could define a <table> element that defines a table of contents. A second schema for furniture could also define an element named <table>. If data from both were to occupy the same XML file, it would be impossible to differentiate which <table> was which.
By defining a unique identifier, a namespace, for each XML vocabulary, we can group the elements under each identifier, so that XML software can identify each vocabulary element being used. (See the XML.com article "XML Namespaces by Example" for more information.)
URIs
Namespaces create another problem. It's fine to suggest that each XML vocabulary should be assigned a unique identifier, but how can you ensure that the unique identifier you choose hasn't already been used? Theoretically, there are no assurances that a namespace identifier hasn't been used by another vocabulary. However, by using a URI (Uniform Resource Identifier) you can greatly reduce the chance of a namespace collision.
A URI can be one of two types: a URN (Uniform Resource Name) or a URL (Uniform Resource Locator). The distinction between the two is a little vague and overlaps in some respects. URLs identify a resource by its location or by an address for accessing the resource. URNs identify a resource by an address that doesn't necessarily access the resource but which must be unique and must always refer to the same resource, even if it moves or becomes obsolete. In this way, a URN could also be a URL, if the URL address was guaranteed to persist and always point to the same resource.
In practice, URLs are the most commonly used kind of URI, particularly for namespace identifiers. Once an organization has purchased a unique domain name, it can create namespace identifiers based on this name. By using URLs which it theoretically owns, the organization can control and manage namespace identifiers under this domain, ensuring no namespace conflicts.
RDF
The Resource Description Framework (RDF) is a model for representing resource metadata, that is, information about things. These "things" can be web pages, people, books, or anything else. The information could be file size, height, color, or any other property that something might have. RDF therefore consists of a number of statements about something:
Notes from a Small Island has an ISBN of 0552996009
Notes from a Small Island has an author of Bill Bryson
Bill Bryson has a birth place of Iowa
Note that each statement (or triple) is constructed from three parts: the resource (Notes from a Small Island), the property name (ISBN), and the property value (0552996009). These statements could be represented in any XML vocabulary:
<book name="Notes from a small island">
<ISBN>0552996009</ISBN>
<author birthplace="Iowa">Bill Bryson</author>
</book>
or
<document identifier="0552996009">
<title>Notes from a small island</title>
<creator name="Bill Bryson">
<born location="Iowa" />
</creator>
</document>
These two examples, by demonstrating the versatility of XML, show part of the problem that RDF solves. If we rely on just XML, these statements can be represented in an unlimited number of vocabularies, each with its own schema and rules. An application that had to search a collection of 100 different XML files for books written by Bill Bryson would need to know the exact element or attribute to search for within each vocabulary, that is, the application would need prior knowledge of each vocabulary.
By introducing an overarching model, RDF provides a superior solution. The RDF model is enforced within the XML syntax by basically restricting the XML rules and by introducing a set of core elements and attributes. The real power of RDF comes from its use of namespaces and URIs. RDF vocabularies can be defined with RDF Schema. Within an RDF instance document, however, these vocabularies can be more easily mixed than in standard XML. Once a vocabulary has been created that defines an author property, as long as the vocabulary is assigned a unique namespace, the property can be used in any RDF file. RDF software, with knowledge of just a single RDF vocabulary, can search all statements in all files for particular authors.
URIs provide the icing on the RDF cake. When an RDF vocabulary is defined, each element within it can be referenced by a URI, uniquely identifying it. Each element can also define any part of a triple, i.e. RDF can be used to create lists of resources (things you want to describe), properties, and property values. A triple can consist of nothing but URI references.
Unlike standard XML, RDF files commonly contain data that can be decomposed into a set of URIs. For example, the previous XML example could be represented in RDF as
<rdf:RDF xmlns:dc="http://purl.org/dc/elements/1.0/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="urn:isbn:0552996009">
<dc:title>Notes from a Small Island</dc:title>
<dc:creator rdf:resource="http://authors.com/b/bbryson.rdf" />
</rdf:Description>
</rdf:RDF>
If we examine one of the triples that an RDF parser would give us, we find:
Item we are describing: urn:isbn:0552996009
Property of this item: http://purl.org/dc/elements/1.0/creator
Value of this property: http://authors.com/b/bbryson.rdf
This has two immediate benefits:
All aspects of the data can be unambiguously identified. For example, in a standard XML document, the author could be stated as "Bill Bryson", "Mr Bill Bryson" or "Bryson, Bill." Software searching for this author would need to be aware of the potential differences in representation and could also run into trouble if a second author existed with the same name. In RDF, assuming that all files use the same URI to reference the author, the author can always be uniquely identified.
If these triple values are also RDF resources, the software can automatically find related information. For example, some other RDF document could contain information on the author's birthplace, which in turn may be represented by another URI. An RDF document concerning US cities could then be consulted, which might contain information such as longitude and latitude, average temperature, etc. So, by making a single statement in RDF, further and related information can potentially be automatically acquired.
The real benefit of these explicit, ongoing relationships of information (the Semantic Web) is enormous. The near future will hopefully bring us software agents, which can query and use a whole range of RDF information for a given question (e.g. "Show me hardback books created by anyone who is related to a politician" or "Which servers can run Solaris and are available in the UK?").
If nothing else, if and when engines such as Google starts to make use of RDF and its power of relations, it will become extremely good at The Kevin Bacon Game. (See the XML.com article "RDF: Ready for Prime Time" for more information.)
by Daniel Zambonini
XSLT
XSLT (Extensible Stylesheet Language Transformations) -- together with XPath and XSL-FO (Extensible Stylesheet Language -- Formatting Objects), constitute a set of technologies named XSL, which transforms and formats XML data.
XSLT in particular is powerful and commonly used. XSLT is an XML vocabulary that can completely transform XML data into another XML format or any other text format. (See the XML.com article " XML.com Style Resource Centre" for more information.)
XPath
XPath defines a non-XML syntax for referring to specific parts of an XML file. Using XPath you could find "the ISBN attribute inside the third book element" or "every book element in the file". When used within XSLT, XPath provides the means for extracting specific data from the input XML.
XPath also contains basic functionality for matching data (testing if an element has a specific value), as well as string and number manipulation.
XSL-FO
Related Reading
XSL-FO
Making XML Look Good in Print
By Dave Pawson
Table of Contents
Index
Sample Chapter
Read Online--Safari Search this book on Safari:
Only This Book All of Safari
Code Fragments only
XSL-FO is an XML vocabulary for the layout and styling of content within a paginated document. XSL-FO data is usually created from an XSLT process; i.e. XML data will undergo an XSLT transformation, resulting in an XSL-FO file. The XSL-FO file can then be processed with a formatting application, to produce a document file such as a PDF.
SVG
SVG (Scalable Vector Graphics) is an XML vocabulary for creating two-dimensional vector graphics. SVG images can also be interactive, animated, and can include text and bitmapped images.
SVG images boast an array of benefits over similar formats, including all the benefits associated with XML (platform independence, flexibility, open nature) and accessibility features. (See the XML.com article "SVG: A Sure Bet" for more information.)
Creating the Diagram
Now let's make use of these technologies to create a diagram that illustrates their relationships. We'll first need to create some raw data that describes each technology in a computer-readable format. We know that XML is a good format for computer-readable data; since we are describing something, RDF can be used for the model.
RDF likes us to specify unique URIs, so we'll use the specification document URL for each technology we are describing. In terms of the information that we need to record, basic properties such as title, subject and relationships are required. Luckily, RDF vocabularies already exist for properties such as these, so we won't need to define our own with RDFS. We'll use the Dublin Core RDF vocabularies:
Basic Dublin Core element set (RDF) for title, description, subject and date properties.
Qualified Dublin Core element set (RDF) for specific relationship properties, such as "conforms to" and "has part".
By using conventional, standard RDF vocabularies for our data, other applications that understand Dublin Core RDF can reuse our data at a later date.
Take a look at our RDF data for the technologies. For each technology we've specified title, description, creation date, relationships, and occasionally a subject. The subject property allows us to semantically group some technologies under common concepts, even if there are no specific relationships between them. We'll make use of the subject data in the diagram.
As you may have guessed, we're going to use SVG for the diagram -- thus, the next step is to convert our RDF data into a visual SVG representation.
We'll use XSLT and XPath to transform our RDF data into SVG objects (squares, lines, and text). The specifics of the XSLT aren't important (you can look at the XSLT that converts the RDF into SVG if you're curious.) What is important is to recognize how and why we've used it. The XSLT contains a series of logical steps that convert our input RDF data into a completely different visualization of the same data. Note that this XSLT has been designed specifically for our input data. Given time and proper planning, you could develop XSLT templates that transform any set of RDF statements into similar visualizations. It is, however, probably better to use an RDF toolkit. XSLT to parse all of the permitted constructs of RDF that you might find in the wild can be extremely complicated.
The SVG diagram, output from the XSLT process. Click on image for a full-size version, or view the SVG diagram (may require a plug-in).
SVG currently has limited support in web browsers and image viewers; as a final step we'll embed the diagram into a PDF document to make it available to a larger audience. An additional XSLT file is used to create the XSL-FO for our document, defining and structuring the page and its contents. Within the XSL-FO, the original XSLT for the SVG diagram is called, embedding the SVG code within the XSL-FO page.
The output (XSL-FO plus embedded SVG) is then processed with an XSL-FO processor. We'll use Apache FOP. FOP converts our plain text XSL-FO into a PDF file, rasterizing the SVG into a diagram on the page (using Apache Batik). We finally have our PDF diagram of the XML technologies.
Conclusion
To recap, we used terms from the Dublin Core RDF Schema (which makes use of XML, Namespaces and URIs) to create a RDF description for each technology. These were converted to SVG using XSLT and XPath. We could have validated our XSLT file with XML Schema (using the XSLT schema). The SVG diagram was finally embedded into an Adobe PDF document with XSL-FO, resulting in a printable file that contains a diagram of the technology relationships.
When XML and RDF data become ubiquitous on the Web, the potential for querying and displaying the information will be enormous. The tools and underlying technologies are already in place. All that's needed is a greater understanding of the potential that it offers. The growth of these technologies is limited largely by our reluctance to commit.
XML.com Copyright © 1998-2003 O'Reilly & Associates, Inc.