XML4J �������һ���Խṹ����ʽ���� XML �ĵ��Ա����ÿ��Ԫ�صĹ��ߡ����Ľ�����һ������ XML �ĵ������ĵ����Ͷ��� (DTD)����ͨ��ʹ�� XML4J ���������������η��� XML �ĵ�����������Ϣ��
Extensible Markup Language������չ������ԣ������ XML���������Ը��ַ���������ҵ��Ϣ�Ĵ��š�һЩʹ�� XML ����Ҫԭ�������
�ֲ� HTML �IJ��㣨XML �ṩ���������ݣ�
���̼ҵ��̼������棬�������ֽ�� EDI �÷�
��Ϊ��ͬ��Ӧ�ó���֮��Ĺ���ͨ�Ź���
HTML ��Ϊ Web �ṩ��Ϣ����dz��ɹ���Ȼ����HTML ��һЩȱ�ݡ���Ϊ XML �ĵ����������ģ����� XML ���ṩ���������ԡ��� Web ����ʹ�� XML ��һ����Ȥ�����������������棺�����������ʹ�ñ�Ǻ�������Ϊ����������һ���֣������Ϳ��Ը���ȷ��ƥ�� Web ���ݡ�����ʹ�ÿ���չ��ʽ������ (XSL) ��ʽ������ʽ���ĵ����Ӷ�������֧�� XML ��������в鿴 XML �ĵ���
���̼ҵ��̼�������ʹ�� XML���Լ��� XML ������ͬ��Ӧ�ó���֮��Ĺ���ͨ�Ź��߶�Ҫ����һ�ֻ��ƿ��Զ�ȡ XML �ĵ���������ͳɱ��ڼ������������ʽ��Ӧ�ó�����Ҫһ�ַ���ÿһ�� XML �ĵ��������ĸ�����Ϣ��Ԫ�أ��ķ�ʽ������ʹ�� XML ��������Խṹ����ʽ���ֲ���״�ṹ�������ĵ���ʵ�ֵģ��Ӷ��������ʺͲ����ĵ��е�ÿһ��Ԫ�ء�
����
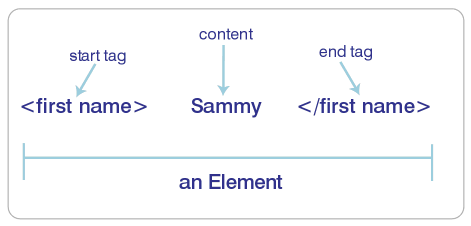
ÿ�� XML �ĵ������ض��ڸ��ĵ���Ԫ����ɡ�ͼ 1 ��ʾ�� XML Ԫ�صĽṹ���������ݵ�Ԫ�ؾ��п�ʼ�ͽ�����ǣ����ڱ��֮��������ݡ��������ݵ�Ԫ��ͨ��������֯�ĵ��ṹ����������һ���ڴ��ں� (>) ֮ǰ����б�� (/) �Ŀ�ʼ��ǣ���ʾû�����ݡ����Խ�Ԫ����֯��ʮ���������ֽ���ļ������Ľṹ����Ƕ�ײ�ο��ɿ�ʼ�ͽ�����ǵ�λ�÷�ӳ������
ͼ 1��XML Ԫ�صĽṹ
�κ�Ԫ�ض�����ӵ�����ԣ���Щ���Խ�һ������Ԫ�ء���ͼ 2 ��ʾ����Ԫ�صĿ�ʼ����ж������ԡ�
ͼ 2���������Ե� XML Ԫ��

ÿ�����Զ������ƺ�ֵ��ɡ�������˫���� (") ��ֵ����ÿ��Ԫ�ؿ��������������ԣ���ȡ��������ߵ���Ҫ��ÿ������߶�����ȷ��Ҫ�������Ϣ��ʾ����Ԫ�ػ������� -- �ⷽ��û���ϸ�涨��
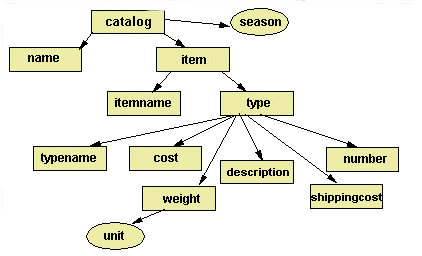
ͼ 3 ��ʾ�˱�����ʹ�õ��ĵ������ĵ�������ƷĿ¼���ݡ��Ѿ������ĵ���������ʾ�ĵ��IJ�νṹ��
ͼ 3 - ��ʾ����Ŀ¼�� XML �ĵ�

�� XML �ĵ�����������ë����Ϣ����ʽ��Ůʽ��ÿ����Ʒ����ë��������Ϣ��λ��һ�Ա���С���ע�� shippingcost ���û�н�����ǣ������ڿ�ʼ����е� shippingcost ֮ǰ��һ��б�� (/)�������û�����ݵĿձ�ǡ������Գ䵱ռλ�������Ժ�ʹ�á�
XML �ĵ�Ӧ�����ĵ����Ͷ��� (DTD) ����֤ XML ��ȷ���DTD ���� XML �ĵ��Ľṹ�����й���Ԫ�ؼ��ϵ�Ĺ�����ض���ijһԪ�صĹ���DTD ��ʾ�ṹ��Ԫ�صIJ�νṹ��Ƕ�ס�
ͼ 4 ��ʾ�˶��� catalog �ĵ��ṹ�� DTD����� DTD ��������Ƕ�ġ��� catalog ��Ϊ�����Ƕ�ṹ���ڽ��� DTD ֮ǰ����Ҫ�������»���ԭ��
Ԫ������������ʽ����ġ�
Ԫ�ؿ�����������Ԫ�أ���Щ��Ԫ����Բ���� () ����������Ԫ����֮��
ÿһ����Ԫ�ض�������صġ���Ԫ�����ƺ���������ַ���ʾ�ij��ֹ����ڽṹ�г��֡���Щ�����ǣ�
���û�������ַ�������Ԫ�ر������һ����ֻ�ܳ���һ�Ρ�
������Ǻ� (*)������Ԫ�س�����κͶ�Ρ�
������ʺ� (?)������Ԫ�ؿ��Գ�����λ�һ�Ρ�
����мӺ� (+)������Ԫ�ر������ٳ���һ�λ��Ρ�
ͼ 4 �ж���� catalog DTD ��ʾ��ijЩ���ֹ�����÷������磬 name ֻ����һ�Σ���Ϊ������û�������ַ����� item ����Գ��ּ��λ���������֡�
ͼ 4. �ĵ����Ͷ���
<!DOCTYPE catalog [
<!ELEMENT catalog (name,item*) >
<!ELEMENT name (#PCDATA) >
<!ATTLIST catalog season (winter|spring|summer|fall) #REQUIRED>
<!ELEMENT item (itemname,type*) >
<!ELEMENT itemname (#PCDATA) >
<!ELEMENT type (typename,cost,description,number,
weight,shippingcost) >
<!ELEMENT typename (#PCDATA) > <!ELEMENT cost (#PCDATA) >
<!ELEMENT description (#PCDATA) >
<!ELEMENT number (#PCDATA) >
<!ELEMENT weight (#PCDATA) >
<!ATTLIST weight unit (pound|kilogram|gram|ton) #REQUIRED>
<!ELEMENT shippingcost (#PCDATA) >
]>
ijЩԪ�ذ����������б�����ж�������ԡ���������ǰ�������ģ��������������ض�������Ӻ���ģ����ұ����� DTD �ж��塣���磬catalog ��һ�� season ���ԣ������Ե�ֵ������ winter �� spring �� summer �� fall ������ʹ���� #REQUIRED �ؼ��֣����Ա����ṩһ��ֵ����ҪΪ�ĵ��е�ÿ��Ԫ�طֱ������������͡�#PCDATA���� Parsed Character Data��������������ַ����ݣ�����ʾ�ַ����ı������ݡ�Ŀǰ��XML �ĵ�ֻ�����ַ����ݡ�
���Ľ���������ƪ�ĵ����õ��Ļ����������Ϣ�����кܶ��鼮���������ڴ��� DTD �����й����ע�����
ʹ�� XML �������
IBM �ڰ��� AS/400 Toolbox for Java ���ڵĸ��ֲ�Ʒ�С��Լ��� IBM alphaWorks ��վ�϶��ṩ�� XMLJ4 �������������� �ο����ϣ�������������� Java ������Ա�д����˿���ֲ���������� Java ����� (JVM) �IJ���ϵͳ�ϡ����������ʹ�� DTD �� XML �ĵ��������ֲ���ʾ�ĵ����ĵ�����ģ�� (DOM) ����DOM �ṩ��һ��������������Ԫ�ص� API��ʹ����Щ DOM API���Ϳ��Է��ʡ����ġ�ɾ�������� XML �ĵ��е�Ԫ�ء�
XML �������ʹ�� DTD ����֤�ĵ�����ȷ�� XML �ĵ������� DTD ��ָ�������й������磬DTD �������ָ����Ч�ı�Ǽ�����Ч��Ԫ��Ƕ�����Լ����ض�Ԫ����ص����ԡ�XML ���������ʹ�� DTD ���������ض� XML �ĵ����� DOM��DOM ��Ӧ�ó����������ڼ�������ѯ���� XML �ĵ�����Ϣ���ĵ���ʾ��
ͼ 5 �������ĵ���һ�� DOM ��ʾ������û�������ṹ�б�ʾ���ݡ����뽫���������Ǵ������ݵ����Ի�ɭ�֣�������һ����һ�ṹ��ͼ 5 �е�ÿ�����ζ���ʾ���е�һ���ڵ㣬ÿ����Բ����ʾһ�����ԡ�Ϊʹͼ�����ܼ�ֻ������Ԫ�غ���������
ͼ 5 - �ĵ�����ģ��
DOM �ṩ�˷�������Ԫ�صķ�����ͨ����ѭ��״���ֲ㣩�ṹ����Щ���������Ը������Ӵ����÷�������������
�����ʾ��
�������ʾ�������������
Ϊ XML �ĵ����� DOM ����
��ӡ���������������ԡ�
���Һ��滻��Ϊ�������ݵ��ض�Ԫ�ء�
��ӡ���������µģ�����
����ʹ�� FindReplaceDOMParse �ࡢIBM XML4J �������������� �ο����ϣ��� DOM API �����ʺͲ��� XML �ĵ���ͼ 6 ����ʾ�� import ��䡣
ͼ 6. Import ���
import com.ibm.xml.parsers.DOMParser;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Element;import org.w3c.dom.NamedNodeMap;
ͼ 6 �����г��� import ����� XML4J ������������� DOM API ֧�ֵ�һ���֡������� XML4J ������������ĵ��ĵ����ҵ���ϸ��Ϣ��
�����ͼ����ʾ�� main() �����Ĺؼ����֡� main() ������Ҫ�ĸ�������
srcfile��XML �ĵ���
targetElement���ڲ��Һ��滻���������õ���Ԫ�أ����ƣ�
valueToFind��ϣ���滻��ֵ
valueToReplace����ֵ
��Щ�����е�ÿһ������ת���� main() �е� String��ִ�иó��������ʱ����ʾ���ǣ�
ͼ 7. FindReplaceDOMParse ����ʱ����
java .FindReplaceDOMParse catalog.xml cost $50.00 $95.00
main() ������˳�����ڸ�������ָ���IJ�����
���������е���һ����Ϊ catalog.xml �ĵ����� DOM ������ͨ������ָ����Դ�ļ� ( srcFile ) �������ɡ���ȷ�Ϸ�ʽ������������⽫ȷ���ĵ�����Ч�ġ�ͼ 8 ���������ڷ��� XML �ĵ��ķ����ĵ�����䡣
ͼ 8. ���� parseV ����
Document document = parseV(srcFile);
ͼ 9 ����ʾ�� parseV() ����ִ�����²��裺
����һ���������ʵ����
���� XML �ĵ� ( srcfile )��
��ȡ DOM���ĵ��������䷵�ظ������ߡ�
ͼ 9. ���� XML �ĵ��Դ��� DOM ��
public static Document parseV(String srcFile) throws Exception{
try {
// Get a new parser and attach an error handler
DOMParser myParser = new DOMParser();
// Parse the file
myParser.parse(srcFile);
// Return the document
return myParser.getDocument();
} catch (Exception ex) {
System.err.println("[Operation Terminated] " + ex);
}
return null;
}
ͼ 10 ������ main() ���������ڴ����ĵ��ķ������á���Ŀ���Dz���Ԫ�أ��ڵڶ��������д��ݣ���Ԫ��ֵ���ڵ����������д��ݣ���������ֵ�ij���ֵ���ڵ��ĸ������д��ݣ������ҵ����滻Ԫ��֮ǰ����ӡ DOM �����ڸ���֮���ٴδ�ӡ����
ͼ 10. ���ڴ�ӡ�� main() ��������
if (document != null) {
// Print the initial state of the document starting at the root element
System.out.println("******************BEFORE*******************");
printElement(document.getDocumentElement());
// Perform a find replace on the document
document = findReplace(document, targetElement, valueToFind, valueToReplace);
// Print the resulting state of the document starting at the root element
System.out.println("*******************AFTER*******************");
printElement(document.getDocumentElement());
} else{
System.out.println(" in main document null");
}}
�������� main() �����б������Խ���ʵ�ʴ����ķ�����
printElement(document.getDocumentElement()) ���� getDocumentElement() �������ݵ��ĵ���DOM �����ĸ�����
document = findReplace(document, targetElement, valueToFind, valueToReplace) ����Ҫ���ĵ�Ԫ�ز���ɸ��ġ�
printElement(document.getDocumentElement()) ��ӡ���µ� XML �ĵ���
��һ����ӡ�İ汾������ͼ 2 ����ʾ���ĵ���������ͼ 7 �ж��������֮����ʽ��ë���ļ۸� 50.00 ��Ԫ�ij� 95.00 ��Ԫ��
ͼ 11 ����ʾ�� p rintElement() ������������Ԫ������Ԫ��ֵ���������ڵ������ĵ���DOM ������
ͼ 11. printElement() ����
private static void printElement(Element element) {
int k;
NamedNodeMap attributes;
NodeList children = element.getChildNodes();
//***** Start this element
System.out.print("<" + element.getNodeName());
//***** Get any attibutes and print them inside the element start tag
attributes = element.getAttributes();
if (attributes != null) {
for (k = 0; k < attributes.getLength(); k++) {
System.out.print(" " + attributes.item(k).getNodeName());
System.out.print("=" + attributes.item(k).getNodeValue());
}
}
if (element.hasChildNodes()) { //***** If this element has a value or sub-elements
System.out.print(">");
//** For each child, if the child is an element call print element to print that
//** portion of the tree, if it is a text node, print the text to stdout.
//** All other node types are ignored for the sake of simplicity.
for (k = 0; k< children.getLength(); k++) {
if (children.item(k).getNodeType() == org.w3c.dom.Node.ELEMENT_NODE) {
printElement((Element) children.item(k));
} else if (children.item(k).getNodeType() == org.w3c.dom.Node.TEXT_NODE) {
System.out.print(children.item(k).getNodeValue());
}
} // end for loop
//***** Add a closing tag
System.out.print("");
}// end else
}// end method
printElement() �ǵݹ鷽�������������������Լ���ֱ�����������е����нڵ�Ϊֹ��DOM �ӿ���Ҫ��������Ҫ���������� Node �ӿڡ�
�Դ��ݵ� printElement() ��Ԫ�ؽ������´�����
���� getChildNodes() �������ذ����ýڵ������Ӵ��� NodeList��
ʹ�� println ����ӡ "<" ���� getNodeName() �����õ���Ԫ�ؽڵ�����
ʹ�� getAttributes() ���������ذ����ڵ����Ե� NamedNodeMap��
ͨ��ѭ������Ԫ�ص������������������ԣ�������Դ��ڵĻ�����
ʹ�� getNodeName() ��ӡ��������
ʹ�� getNodeValue() ��ӡ�Ⱥ� (=) ������ֵ��
NodeList children ������Ԫ�ص��Ӵ������ڵ� 1 ����ȷ�������Ԫ�����Ӵ���ͨ������ hasChildNodes() ������ȷ����������ѭ���д���ÿ���Ӵ������б��еĽڵ��� ELEMENT_NODE �� TEXT_NODE��
ͨ������ printElement() ����������Ԫ�ؽڵ㣬��ȷ����Ԫ�ؼ����Ӵ�����������
���ı��ڵ�ֻ����ӡ��������Ϊ���ǽڵ�ֵ���������µĽڵ㡣
ÿһ������Ԫ����Ϣ�����ԵĽڵ㶼����صĽ�����ǡ�
������Щû��Ԫ��ֵ��Ԫ�أ���Ԫ�����Կ�Ԫ�ص���ʽ��ӡ������˵����
�뿴һ�µ� 5 ������ȷ����δ���Ԫ�ء����뽫���ڵ������� ELEMENT_NODE ���� TEXT_NODE���Ա������ȷ�Ĵ���������Ľڵ����ӵ����Ԫ�غ��ı�����ͼ 12 ��ʾ����ͼ��ʾ���ǵ绰���롣�绰���������˾��������ڵ��Ԫ�أ�һ����Ԫ�أ���һ����Ԫ���ı����绰���룩��ͼ 12 ������ʹͼ 5 �п��ܽ��еĴ�����������
ͼ 12. DOM ��Ƭ��ʾ��
һ����ӡ�˳�ʼ�ĵ��������� findReplace() ��������ָ����Ԫ��ֵ������ main() ������˷������ݲ���֮�⣬�˷�������ִ���� printElement() �������ƵĹ��ܡ��ĵ���DOM ������Ϊ���������ݡ�ͼ 13 �����˴����������滻��Ĵ��롣�·����Դ�����ʾ����ʾ���������۵��¹��ܡ�
��Ϊ��δ���Ĵ��� printElement() �����еĴ������ƣ���������ֻ���� findReplace() ������ͻ����ʾ�Ĵ��롣����������ʽ����ͻ����ʾ�Ĵ��룺
�Ӹ�Ԫ�ؿ�ʼ��Ԫ�ط��� getElementsByTagName() ������������Ԫ�أ���������� NodeList �У���
һ��ȷ�� NodeList �еĽڵ��� TEXT_NODE���ͽ��ýڵ��봫���ֵ���бȽϣ���ȷ���Ƿ�Ҫ���ĸ�Ԫ�ء�ͨ���� NodeList �еĸýڵ�ʹ�� equals() ������ʵ����㡣
ʹ�� setNodeValue() ����������ֵ���ó���ֵ
ͼ 13. findReplace() ����
static private Document findReplace(Document document, String elementName, String
valueToFind, String valueToReplace) {
int i; int k;
NodeList children;
Element docRoot = document.getDocumentElement(); //*** Get the root element
NodeList elements = docRoot.getElementsByTagName(elementName);
if (elements != null) {
//** For each element matching the search element
for (i = 0; i<elements.getLength(); i++) {
if (elements.item(i).hasChildNodes()) {
children = elements.item(i).getChildNodes();
for (k = 0; k
����Ψһû�����۵ķ����� usage() �������ڴ��������з�������ʱ�����ø÷������÷�������һ�� println��������ӡ�ڵ��ø���ʱ���ݵ�ֵ��
������
�����ṩ��һ��ʹ�� XML ������� (XML4J) ��ʾ�����Լ��ɸ���������� DOM API ���ṩ�ĸ��ַ�������� XML �ĵ��Ĺ��ܡ����ظ��������ʱ�������������е��ĵ��������й� XML4J ����֮��ص���ͷ�������ϸ��Ϣ��
[�������Ѿ���������2005-10-25 12:13:37�༭��]

 [����] ����XML��̳ - רҵ��XML���������� ��
XML.ORG.CN������ - XML���� �� �� DTD/XML Schema �� �� ʹ�� IBM XML ������� (XML4J)
[����] ����XML��̳ - רҵ��XML���������� ��
XML.ORG.CN������ - XML���� �� �� DTD/XML Schema �� �� ʹ�� IBM XML ������� (XML4J)



 (���ı���)
(���ı���)



 ����
����  ʹ�� IBM XML ������� (XML4J)(13544��) �� anchen0617��2004��11��13��
ʹ�� IBM XML ������� (XML4J)(13544��) �� anchen0617��2004��11��13��
 ������
������